本文共 4106 字,大约阅读时间需要 13 分钟。
论文名称:Few-shot Learning for Multi-label Intent Detection
论文作者:侯宇泰、赖勇魁、吴禹杉、车万翔、刘挺
原创作者:侯宇泰
论文链接:https://arxiv.org/abs/2010.05256
代码链接:https://github.com/AtmaHou/FewShotMultiLabe
小样本学习(Few-shot Learning)近年来吸引了大量的关注,但是针对多标签问题(Multi-label)的研究还相对较少。在本文中,我们以用户意图检测任务为切入口,研究了的小样本多标签分类问题。对于多标签分类的SOTA方法往往会先估计标签-样本相关性得分,然后使用阈值来选择多个关联的标签。
为了在只有几个样本的Few-shot场景下确定合适的阈值,我们首先在数据丰富的多个领域上学习通用阈值设置经验,然后采用一种基于非参数学习的校准(Calibration)将阈值适配到Few-shot的领域上。为了更好地计算标签-样本相关性得分,我们将标签名称嵌入作为表示(Embedding)空间中的锚点,以优化不同类别的表示,使它们在表示空间中更好的彼此分离。在两个数据集上进行的实验表明,所提出的模型在1-shot和5-shot实验均明显优于最强的基线模型(baseline)。
本期AI TIME PhD直播间,我们有幸邀请到了该论文的作者,哈尔滨工业大学的博士生侯宇泰,为大家分享这项研究工作!

侯宇泰:哈尔滨工业大学社会计算与信息检索研究中心(SCIR)博士生,导师为车万翔教授。主要研究方向为数据稀缺情景下的自然语言处理问题,任务型对话系统等。相关研究成果发表在ACL、EMNLP、AAAI、COLING等会议上。

1.Introduction
1.1 背景一:用户意图识别
用户意图识别是任务型对话理解的关键组成部分,它的任务是识别用户输入的话语属于哪一个领域的哪一种意图 [1]。
当下的用户意图识别系统面临着两方面的关键挑战:
频繁变化的领域和任务需求经常导致数据不足
用户在一轮对话中经常会同时包含多个意图 [2,3]

图1. 示例:意图理解同时面领域繁多带来数据不足和多标签的挑战
1.2 背景二:多标签分类 & 小样本学习
小样本学习(Few-shot Learning)旨在像人一样利用少量样本完成学习,近年来吸引了大量的关注 [4,5]。
但是针对多标签问题的小样本学习研究还相对较少。
1.3 本文研究内容
本文以用户意图检测任务为切入口,研究了的小样本多标签分类问题,并提出了Meta Calibrated Threshold (MCT) 和 Anchored Label Reps (ALR) 从两个角度系统地为小样本多标签学习提供解决方案。
2. Problem Definition
2.1 多标签意图识别
如图2所示,目前State-of-the-art多标签意图识别系统往往使用基于阈值(Threshold)的方法 [3,6,7],其工作流程可以大致分为两步:
计算样本-标签类别相关性分数
然后用预设或从数据学习的阈值选择标签
2.2小样本多标签用户意图识别
观察一个给定的有少量样例的支持集(Support Set)
预测未见样本(Query Instance)的意图标签

图2. 小样本多标签意图识别框架概览
3. 方法

图3. 我们提出的小样本多标签识别模型
3.1 阈值计算
(1)挑战:
多标签分类任务在小样本情景下主要面临如下挑战:
a. 因为要从数据中学习阈值,现有方法只适用于数据充足情况。小样本情景下,模型很难从几个样本中归纳出阈值;
b. 此外,不同领域间阈值无法直接迁移,难以利用先验知识。
(2)解决方案:
为了解决上述挑战,我们提出Meta Calibrated Threshold (MCT),具体可以分为两步(如图3左边所示):
a. 首先在富数据领域,学习通用的thresholding经验

b. 然后在Few-shot领域上,用Kernel Regression 来用领域内的知识矫正阈值 (Calibration)

这样,我们在估计阈值时,既能迁移先验知识,又能利用领域特有的知识:

3.2 样本-标签类别相关度计算
(1)挑战:
如图4所示,经典的小样本方法利用相似度计算样本-标签类别相关性,这在多标签场景下会失效。

图4. 经典的基于相似度的小样本学习模型:原型网络
如图3所示,例子中,time和location两个标签因为support example相同,导致这两个类别由样本得到的表示相同不可分,进而无法进行基于相似度的样本-类别标签相关度计算。
(2)解决方案:
为了解决上述挑战,我们提出了Anchored Label Reps (ALR)。具体的,如图三右边所示,我们
a. 利用标签名作为锚点来优化Embedding空间学习
b. 利用标签名语义来分开多标签下的类别表示
4. 实验
4.1 主实验结果
实验结果显示,我们的方法在两个数据集上显著的优于最强baseline。同时可以看到,我们的方法很多时候只用小的预训练模型就超过了所有使用大预训练模型的baseline,这在计算资源受限的情景下格外有意义。
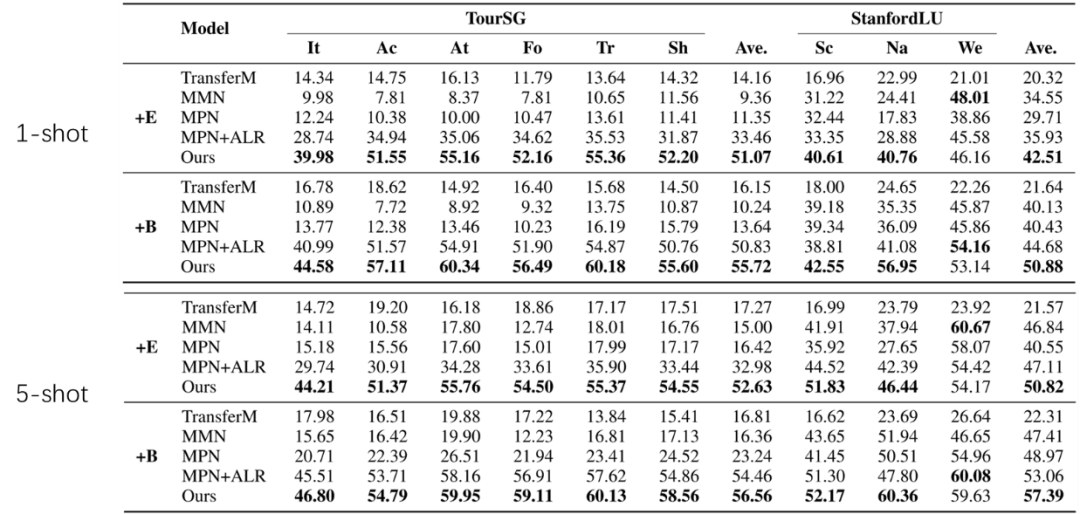
表1. 主实验结果。+E 代表使用 Electra-small (14M);+B为 BERT-base (110M)
4.2 实验分析
图5的消融实验显示所提出的ALR和MCT都对最终的效果产生了较大的贡献。

图5. 消融实验
在图6中,我们对Meta Calibrated Threshold中各步骤对最终标签个数准确率的影响进行了探索。结果显示Meta学习和基于Kernel Regression的Calibration过程都会极大地提升最终模型的准确率。
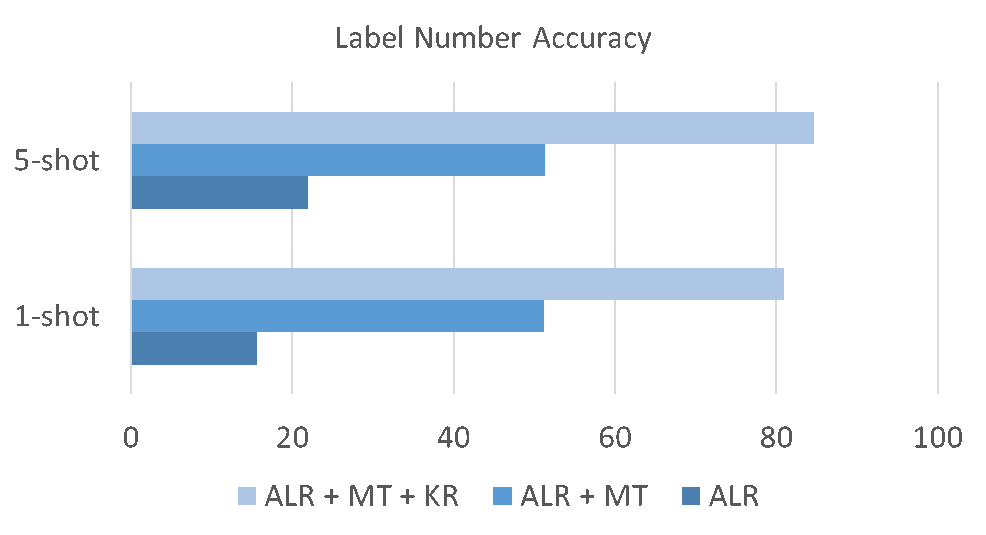
图6. 标签个数准确率结果
参考文献
[1] Young, S.; Gasiˇ c, M.; Thomson, B.; and Williams, J. D. ´ 2013. Pomdp-based statistical spoken dialog systems: A review. In Proc. of the IEEE, volume 101, 1160–1179. IEEE.
[2] Xu, P.; and Sarikaya, R. 2013. Exploiting shared information for multi-intent natural language sentence classification. In Proc. of Interspeech, 3785–3789.
[3] Qin, L.; Xu, X.; Che, W.; and Liu, T. 2020. TD-GIN: Token-level Dynamic Graph-Interactive Network for Joint Multiple Intent Detection and Slot Filling. arXiv preprint arXiv:2004.10087 .
[4] Vinyals, O.; Blundell, C.; Lillicrap, T.; Kavukcuoglu, K.; and Wierstra, D. 2016. Matching networks for one shot learning. In Proc. of NeurIPS, 3630–3638.
[5] Bao, Y.; Wu, M.; Chang, S.; and Barzilay, R. 2020. Few-shot Text Classification with Distributional Signatures. In Proc. of the ICLR.
[6] Xu, G.; Lee, H.; Koo, M.-W.; and Seo, J. 2017. Convolutional neural network using a threshold predictor for multilabel speech act classification. In IEEE international conference on big data and smart computing (BigComp), 126–130.
[7] Gangadharaiah, R.; and Narayanaswamy, B. 2019. Joint Multiple Intent Detection and Slot Labeling for GoalOriented Dialog. In Proc. of the ACL, 564–569.
本期责任编辑:李忠阳
本期编辑:彭 湃
『哈工大SCIR』公众号
主编:车万翔
副主编:张伟男,丁效
执行编辑:高建男
责任编辑:张伟男,丁效,崔一鸣,李忠阳
编辑:王若珂,钟蔚弘,彭湃,朱文轩,冯晨,杜佳琪,牟虹霖,张馨
AI TIME欢迎AI领域学者投稿,期待大家剖析学科历史发展和前沿技术。针对热门话题,我们将邀请专家一起论道。同时,我们也长期招募优质的撰稿人,顶级的平台需要顶级的你!
请将简历等信息发至yun.he@aminer.cn!
微信联系:AITIME_HY
AI TIME是清华大学计算机系一群关注人工智能发展,并有思想情怀的青年学者们创办的圈子,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法、场景、应用的本质问题进行探索,加强思想碰撞,打造一个知识分享的聚集地。

更多资讯请扫码关注

我知道你在看哟

◎直播回放:
https://www.bilibili.com/video/BV175411A7BA?share_source=copy_web
(点击“阅读原文”下载本次报告ppt)
转载地址:http://lzwdb.baihongyu.com/